What I learned from analysing 1.65M versions of Node.js modules in NPM
NPM and open source modules are one of Node.js’ greatest strengths — and also one of it’s greatest weaknesses. took it upon myself to explore how the NPM really works on a granular level and at scale. It turned out there was a lot to discover. The following blog post is a long one, but hang in there, it will be worth it. Grab a cup of coffee and enjoy the deep dive into the NPM ecosystem.

Table of contents:
For those who wish to know ahead of time what is coming:
- Prologue
- Part 1 — NPM Cache
- Part 2 — How NPM handles install
- Part 3 — The birth of npm-ducttape
- Part 4 — The part where I analyse all modules and versions
- Part 5 — Findings
- Part 6 — Summary
Prologue: How it all began
Let’s start at the beginning. It all started by me trying to solve the age old question of how to properly include modules for deploy processes. We all know that including the whole node_modules folder is not a good solution as it breaks compiled libraries. At the same time having a package.json + npm-shrinkwrap.json and using NPM install is ALSO not as reliable as one would hope. NPM does go down from time to time, network fails, packages change etc.
At the same time my colleague was also working on a tool that would help developers keep their packages ahead of known security vulnerabilities using the Node Security Project advisories. This internal project happened to land on my doorstep — so instead of doing a shallow analysis I decided to go deep. And here we are.
Part 1 — NPM cache
tl;dr
- NPM has a cache where it stores all package files indefinitely by default
- all GET requests, including npm update hit the cache
- you can modify the cache location and behaviour (along with other npm configuration settings) using a .npmrc file
- there are bundledDependencies
First off, I did the unthinkable and actually read the entire NPM documentation (so you don’t have to). To my surprise, I found some useful information from there, such as:
- Some useful commands like npm version — which allows you to update your package.json/npm-shrinkwrap.json, create a git commit and tag it with the new version, all with a single command. Or npm pack — which allows you to download the requested package as a .tgz to the root directory of current packages.
- Various ways to configure NPM — cache location and timeout, registry url, ignore-scripts, save-exact, sign-git-tag etc. Or that you can actually set these properties per project using a .npmrc file.
- How NPM resolves package installation folders in v2 vs v3, and how the v3 dependency resolver tries to avoid duplicates and how it is non-deterministic.
- That there are peerDependencies, bundledDependencies, optionalDependencies, devDependencies and finally dependencies. As well as what are the differences between those and why it matters.
- All the various ways you can specify your dependencies in the package.json file.
All in all, I do recommend you take the time and read it through yourself — if nothing else, it will give a more thorough understanding on how one of the most used package managers works.
At first glimpse, there are bundledDependencies, which by definition are dependencies included within the module. Sounds exactly what one would need. Except the bundling occurs when the package is published — unless you want to publish the package to the NPM repository or have a clone set up, then it won’t actually help.
Another one of the more interesting things I found for my original purpose was the cache mechanism. Did you know that by default, NPM keeps all the packages and metadata it ever downloads in its cache folder indefinitely? Well it does. However, if the data is older than 10s, then it will check with the repository if there have been changes before it uses the cache.
From there I got an idea that maybe it would be possible to use the cache mechanism to store files in the local directory and install from there. After giving it a try, it was actually quite easy to set up — created a .npmrc file into my project test folder it was good to go.
So what happens is that when you install things, NPM will store the tarballs and metadata into the packages folder. When I delete the node_modules folder and run npm install again then it won’t talk to the repository. So far so good. But then I ran into a wall — what happens if I want to update something? Running npm update will surely ignore the cache and ask repository, right? Right?
Well, actually no. It seems that if you set the cache, then every GET request will use the cache instead. This means you have no way to update your packages unless you manually overwrite the cache-min setting. How does this make sense? We will find out in the next section — How NPM handles install.
The approach we took revealed one additional problem — the cache folder will include everything that has ever been installed under the packages directory. Even if you later uninstalled the module. This means that the folder has to be manually cleared to avoid repository bloat.
Although our first encounter with caching arrived at dead end, we learned that NPM:
- has an infinite cache where it stores all tarballs and metadata files
- uses .npmrc file in the current package folder to override its config options (you can also use command line options)
- uses the cache for all GET requests, including update
Part 2 — How NPM handles install
tl;dr
- dependencies are mostly installed serially
- when installing a module, all the metadata for the module is downloaded (including readmes and package.json-s of ALL versions of the said module)
- shrinkwrapped install is much more efficient
In the previous section we reached a dead end because NPM unexpectedly uses cache too much — even for the update command, which doesn’t seem to make sense. Looks like we don’t have enough information! Time to dig deeper and explore how does NPM actually install things.
I opened the NPM codebase and damn — that’s a lot of code. Shifting through it would probably take forever. Not really that keen on working on this forever, so I passed. Instead I figured it would be easier to monitor network traffic and what goes on when NPM does its magic.
The plan was to use a local server as NPM registry and have the local server talk to the real NPM registry and log what it does.
Let’s begin by creating a .npmrc file
Followed by launching a server to pipe everything between the actual registry.
This gives a nice list of all the GET requests that NPM does to the registry. And it was actually quite surprising to see how NPM handles the install.
Here’s a simplified overview of actions triggered by the npm install:
- Order dependencies alphabetically
- Check if any dependencies have already been installed
- Download metadata for all the required dependencies
- Figure out best match (latest possible version for a given semver range) and download the tarball for each dependency
- Take the first dependency alphabetically
- Once the module has been downloaded and unpacked, check its dependencies:
a) If there are dependencies → back to point 1. , but now in the context of the module
b) If no dependencies → continue - Take the next dependency alphabetically:
a) Got dependency → move back to step 6
b) No more dependencies → continue - Check for install scripts and if any exist, run in order
- Module has been installed
For the visual types, here’s a gif overview of an example install where the order steps have already been resolved:
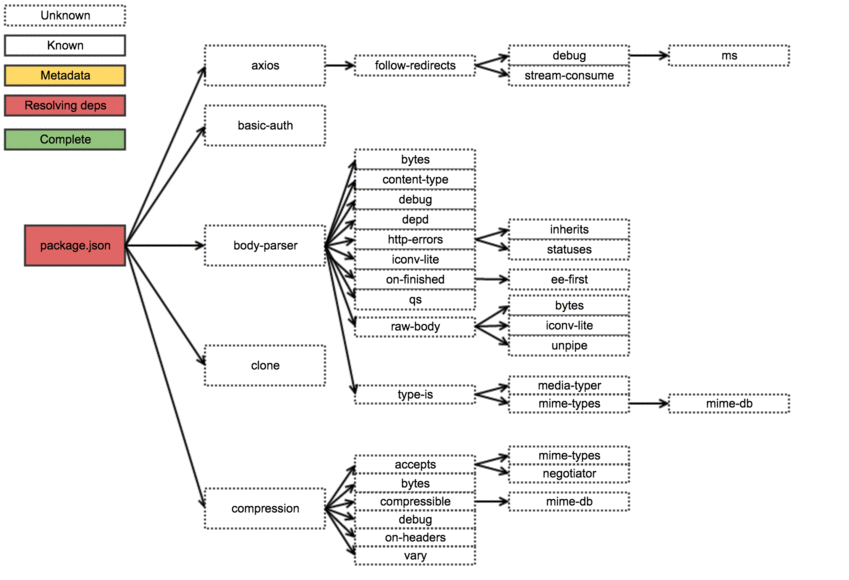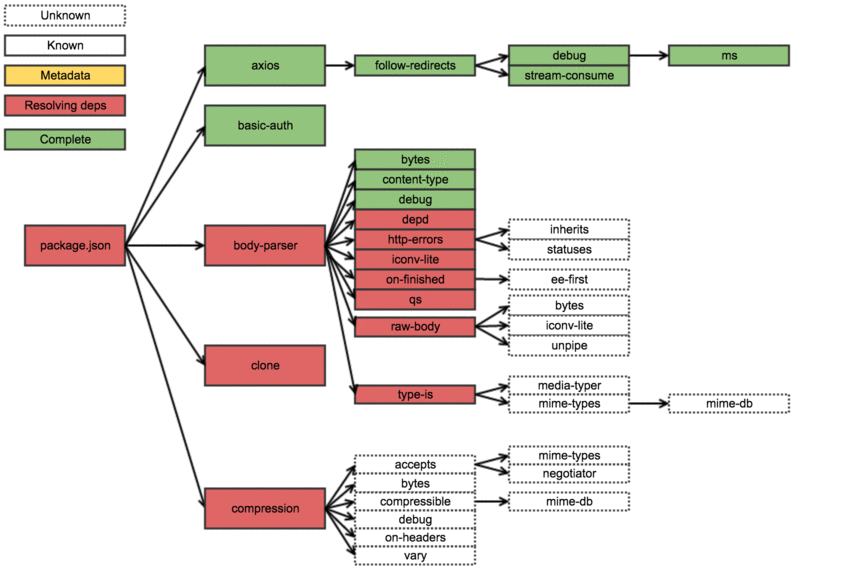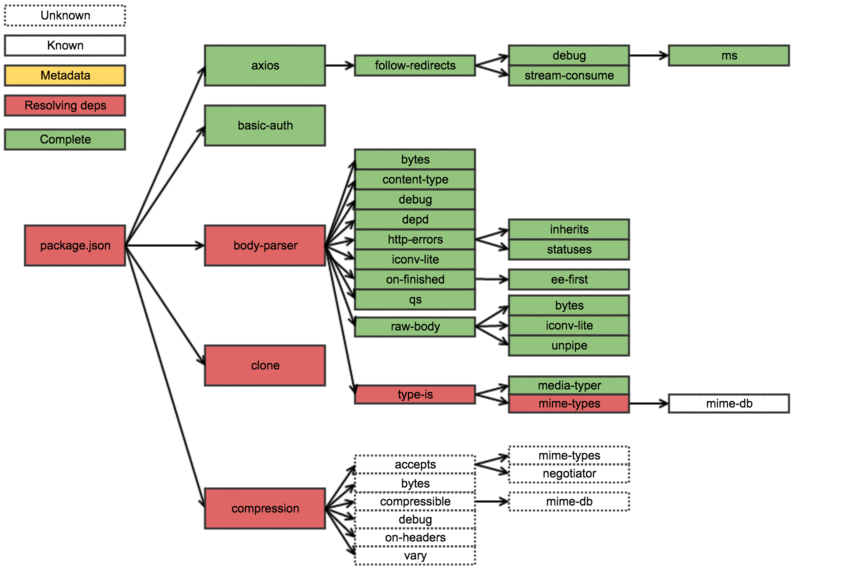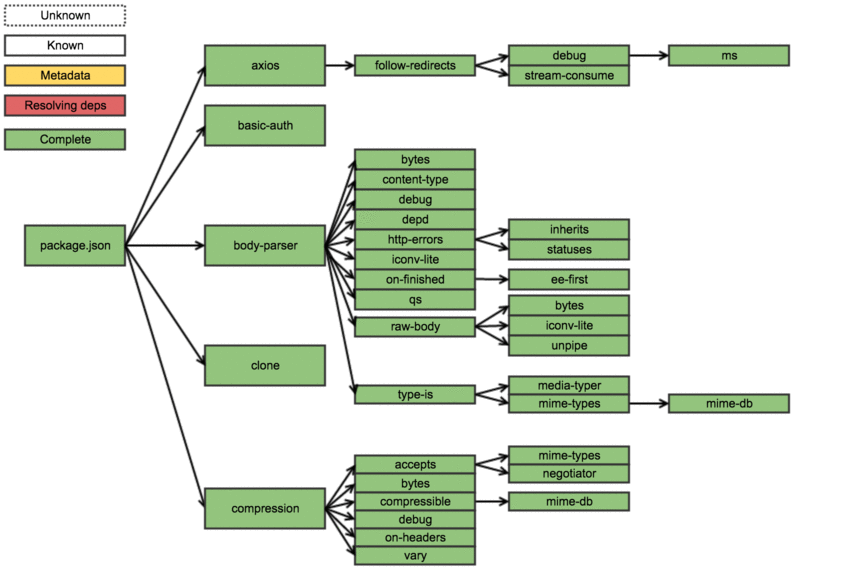
So what was the key takeaway in all this? First off it is a less than optimal way to install packages: the process is mostly serial and (something that doesn’t come out from the previous explanation) when it downloads metadata, it really does download everything about the module it could ever want — this includes all data about all the versions of the package, including readme-s etc. For example the express metadata resides here: http://registry.npmjs.org/express, and it is 53.7kb gzipped or 534kb ungzipped.
That is a lot of metadata.
In fact, out of the 704kb of network traffic from the installation gif example above, 132kb is metadata. That is ~19% of the entire traffic.
Of course this varies depending on how many colliding dependencies you have in the tree, but I’d still say that is A LOT.
Now the question remains — why does it download the whole metadata? With no professional ties to NPM, I can only speculate, but my (semi-educated) guess would be that:
- They want all versions and dependencies to resolve the range optimally and not create subsequent requests afterwards when it encounteres a different range
- Match node versions
- Shasum for package content comparison
- It is simply easier to download everything and sort it out on location
Which all probably boils down to a fact that they have not yet gotten around to optimizing it.
Let’s us continue with our experiment. Since we had our intercept server set up, we could modify the data as we saw fit before actually serving it to our local NPM. After playing around with it a bit, it turned out that most of the metadata just sits there, unused. In fact we could remove over 70% of it on the go and our local NPM would keep on working as if nothing changed. Now that’s what I call lazy optimisation.
If all this serial installing and metadata overflow seems a bit suboptimal to you then don’t worry — shrinkwrap to the rescue. Running npm shrinkwrap will actually write down the version for each model and the url where it got the tarball. So when you do have a npm-shrinkwrap.json file in your project directory, then almost everything will be downloaded in parallel and no metadata will be included. Hooray!
Well…almost everything, because it still follows the pattern of downloading same level modules together and then dealing with dependencies in alphabetical order. So if you have multiple versions of a dependency, then the second version will be downloaded after the previous has been resolved.
The following example shows how bytes@2.2.0 will be downloaded only after all the other packages are downloaded and unpacked.
This, however, still means a lot faster install — on my machine the installation time for this example went from 5s on average down to 2s. That’s a speedup of 2.5x!
All this gave enough information to actually solve the first of the initial quests — how to include modules with your code for deployment. Queue npm-ducttape.
Part3 — The birth of npm-ducttape
EDIT: I was notified of a more mature module solving the same problem called shrinkpack, be sure to check it out. However if you need a lightweight solution (25 dependencies vs 0) then ducttape might be your tool.
tl;dr
- You can use the npm-ducttape to include all your dependencies into your repository for deploy
- The ducttaped repository will install and compile all modules from local content
Including modules for deployment with Node.js projects has been somewhat of a gamble. Using simply package.json is out of the question, because then you can’t be sure what you will end up installing. An option is to use shrinkwrap.json, which locks down all the versions of every installed module — however you will still depend on the network and the NPM repository being there.
But why don’t you just include your modules in the repository? Well you could, if you don’t have any modules that use build systems to link to system libraries or use C libraries that compile. All those will most probably break when moving from dev to deploy. Then there’s also the bloated commits whenever you install a new module or upgrade one. So it is not that simple.
However, as it turns out that shrinkwrap actually includes urls to the required resources and doesn’t otherwise talk to the registry, then we could try to use it. A small test later it was confirmed that shrinkwrap like package.json accepts file: urls. Armed with this knowledge all we need to do is:
- run shrinkwrap
- download all the files listed in npm-shrinkwrap file
- move all the package files under a specified folder
- rewrite npm-shrinkwrap file so that urls to point to local files instead
- ???
- profit
Doing this manually is tedious — especially if your project dependencies are in the hundreds. So I wrote a script for doing exactly that: npm-ducttape.
Now it is quite easy to include dependencies in your repository. The bright sides of using this script include:
- you can be sure that those are the packages that were installed locally
- compiled/linked modules work fine, as the installation process is the same
- no connection to NPM needed — installation uses local files, so no need to talk to NPM
- it’s faster — when you have nothing to download, install tends to be faster
- commits only include references to tarballs
Part4 — The part where I analyse all modules and versions
tl;dr
- there were 1.65M versions of NPM modules at the time
- used Google Cloud and various scripts to analyse almost all of them
So what does it take to analyse NPM and all its modules and versions? To begin with, you need data about what is in the repository. This is actually surprisingly easy, because NPM provides you with a simple way to set up your own copy of it. All it takes is to:
- install couchdb
- clone npm-registry-couchapp
- run the specified scripts to create views in couchdb
- set up data replication from the registry
- wait for the data to download
Now that we have all the meta-information about NPM modules, we can actually export the data into a different database where it is possible to run the desired queries and compare various data points.
But this would only provide a part of the results if we also would want to analyse code: check files, run some regex, get size information etc.
To get the full results we would have to:
- download metadata from the repository
- analyse metadata
- download the code for all versions of the module
- unpack and analyse the code
Easy right? Right?
Not so fast! Turns out that downloading and analysing a version takes on average about 1s. That’s not a lot, but when there are 1.65M versions, then it means ~20 days of non stop download and analysis. I didn’t have that much time.
Luckily Google helped me out — I happened to have 300$ trial money Google Cloud first-time sign up bonus. So I decided to put it into good use by creating a script to do the following:
- divide the whole repository into 30 chunks
- provision a machine for each chunk
- install and start the analysis process in them all
- then collect the results and destroy the corresponding machines
This allowed me to do bulk of the analysis in a day — thank you Google.
PS! Doing this in Google Cloud was surprisingly simple, so cudos to Google for that as well
But I only got a bulk of the analysis done this way, because you see NPM lacks this thing called validation. There are no checks on the validity of data or code. I’m not sure there are any checks at all — I found modules with invalid semvers, dependencies like “../../../etc/passwd”, licences like: ‘hglv2<! — \” onmouseover=alert(1)”’, packages with invalid tar headers etc.
This in turn created a mind boggling amount of edge cases, which had to be handled. Especially since I wanted to analyse whole dependency trees — which of course meant that the dependency requirements had to be solved. Oh no, not the dependencies!

After spending weeks fixing various edge cases and rerunning tests (…and losing more hair than usual), the analysis is finally complete and we can move on to the last part.
Part 5 — Mirror mirror on the wall, whats the fairest module of them all
tl;dr
- lots of dead code in NPM
- everything depends on everything
- NPM is a wild mix of everything
- etc
Having learned how deep the NPM rabbit hole goes, it is time to look at the findings. The analysis revealed a lot of interesting statistics, averages, as well as creations that are simply funny, baffling things and scary. So let’s take a closer look at what NPM jungle has to offer.
PS. For the following statistics, I analysed only the latest version of each module.
First off there is actually a surprising amount of placeholder modules in NPM — almost 2% of all modules have no content besides a package.json and maybe a licence. While that doesn’t necessarily mean that they are placeholders then mostly they are. Some, however, have scripts and the package.json is the whole content of the package.
Speaking of licences — MIT is by far the most popular one with over 50% of modules. Then of course we have a large chunk of missing licence information and the last quarter is divided between myriad of less popular licenses. For me the most interesting one was WTFPL (do What The Fuck you want to Public Licence), which is surprisingly popular, with nearly a 1000 modules sporting it.
Next up I looked at the age of modules — more specifically how long has it been since they since they were last updated? To no great surprise, things get old and people stop paying attention to them. Looking at the graph below, we see that about 40% of modules were not updated last year.
Let’s now shift over to what we actually use NPM for — dependencies. Turns out that over half of the modules in NPM only have 0–1 dependency and the mean is only 2.42. And then there is a module called mikolalysenko-hoarders, which has 389 wildcard dependencies.
The low number of dependencies in a package.json is actually deceiving, because if we calculate the full tree of dependencies of dependencies installed for a module, the picture is drastically different.
The mean number of packages installed for a module is 35.3 , with the maximum being a whopping 1615 for npm-collection-explicit-installs — a module that collects popular NPM modules under one package.
While the outliers do skew the data and over 50% of modules install 4 or fewer packages, over 10% of the modules pack 100+ packages, which I find rather disturbing. Especially when put into context of my average project (not just a package, but an actual service) where I usually have a heck of a lot more dependencies than 2–3 in my package.json and that means the actual amount of dependencies is very high.
Another equally interesting dependency related nuance is that the mean amount of original code vs dependency code is about 45%. (Note: I calculated this based on unpacked file sizes with no regard to file types etc)
The data itself is very polarised — there are loads of modules that have only original code, which is consistent with our original dependency graph (modules that have none). And then there are loads of modules that are completely overshadowed by their dependencies. It does in no way mean that they are poorly done, just that their dependencies are either large or plentiful or have large/plentiful dependencies of their own.
Now this particular metric should be taken with a gracious pinch of salt, because we all know that estimating the amount of work or usefulness by the size of the package is an act of futility.
But the last few graphs do show that the packages do depend a lot on each other. So what are the top packages that creep into dependency trees most often?
Top 10
- readable-stream — Node.js core stream functionality as a separate package
- async — Control flow management
- isarray — Array.isArray
- inherits — Node.js core util.inherits functionality as a separate module
- glob — Match files using the patterns the shell uses, like stars and stuff.
- minimist — for parsing command line arguments
- lodash — utility function collection
- minimatch — A minimal matching utility.
- commander — For parsing command line arguments
- assert-plus —A wrapper around core assert to provide convenience functions
What to make out of this? Well apparently we are not confident in the language itself. There are a lot of people who need to depend on a separate module to check if something is an array. That function has been in the language since Chrome 5 (2010) FFS.
And those of you who say that you have to consider ancient systems — well write/copy the function. It’s here in all its glory.
Or don’t. I mean, for offloading that gigantic effort of including it in your code, you will instead get to download 2kb of metadata and 2kb of files, with a chance that something is down and your build breaks.
It’s even in the core util module if you feel like using that, because looking at Nr 1 and Nr 4, a lot of people don’t. And while inherits was written for the browser, I have serious doubts that it is only used in that context. Here is the module in its entirety for non-browser environments:
For the browser, there is a separate version with 23 lines.
I don’t want to rant on this topic for much longer, but we all remember the left-pad incident, right? It proved that having lots of dependencies might actually not be the best thing.
Having your build break down on someone else’s account is indeed frustrating. But do also consider that your applications attack surface gets exponentially larger with all those modules. An attacker won’t have to compromise you directly — it will be enough to compromise any one of your dependencies. And that means it will be enough to compromise any one of the developers of the said modules. It’s a terrifying world out there that is made even more terrifying by the possibility of lifetime scripts in package.json.
For those who do not know — you can specify commands that get run during install or uninstall of a module. These scripts can include anything and will be run with the user’s privileges.
Looking at packages in the repository, about 2% contain such scripts and they vary greatly in purpose and implementation. One of the funnier ones I found was on a package called closing-time. What it does is download and execute a shell script, which in turn downloads Semisonic’s — Closing Time and adds a row in crontab that starts playing the song every day at 5pm.
Naturally there are also packages that try to elevate the level of danger this all brings — by logging out your ssh keys for example.
And while my quick analysis didn’t find any purposely malicious scripts, I did find horrors that for example on install run the NPM install again against a different repository.
If that’s not enough, there was recently an interesting NPM Worm concept attack, which could use the lifetime scripts to propagate through the NPM packages.
Whether you like it or not, scripts are dangerous and thus I dearly recommend running install with the ignore-scripts flag or setting it true as a default.
npm config set ignore-scripts trueSpeaking of bad dependencies — there are 4k modules that actually have dependencies pointing out of the NPM ecosystem. For example, dependencies are allowed to point to GitHub, external URL, the file system etc.
I understand that it is a nice feature to have in your own development — don’t want to publish everything to NPM, no problem, just point to your own projects. But I seriously think published modules should not have dependencies from outside the system. Not only because I lost half my hair trying to handle the various cases in the dependency tree, but because we as users lose control.
Semver has no meaning if your dependency points to the master branch of a repository. It can change at any point and you’re just going to have to hope that the owner doesn’t suddenly introduce breaking changes or include something malicious.
But not everything in NPM is dark and out to get you. There were some weirdly modules that stood out and gave a good laugh during the analysis.
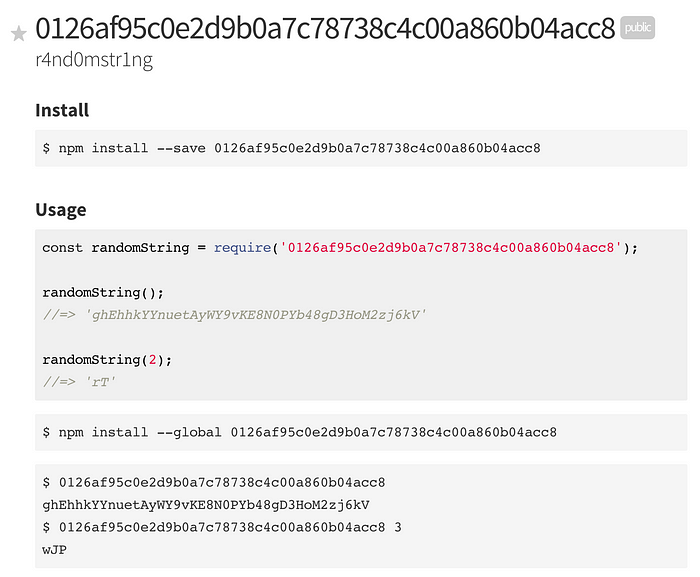
For example a module called 0126af95c0e2d9b0a7c78738c4c00a860b04acc8 — which ironically exports a function to produce a random string.
Or the biggest module of them all, which after unpacking comes in at 8.6GB of data. You might have guessed it — it’s called:
yourmom @ 1.0.0

You’ve got to give credit to the guy — the troll is strong with him. The readme even includes nice puns:
It’s very easy to use yourmom, in fact you can do it in under 5 minutes (provided your hardware can handle the sheer weight of yourmom).
— from the README.md of yourmom
Leaving yourmom aside, we also have a lot of modules that try and test various aspects of the NPM itself. There were dozens of examples of basic script injections and path traversals etc in the various fields of the package.json. However, for now, the great majority of modules out there are just what their authors advertise — blocks of code that solve problems in their best known or easiest way possible.
Part 6 — Summary
tl;dr
- it’s a summary
We have reached the end of our trip down the rabbit hole and hopefully come out the other end a bit wiser, or at least mildly entertained. So let’s recap what we learned along the way.
Well for, one NPM is dark and full of terrors — it’s a wild mix of everything the JavaScript community has to offer. Some great, some bad, but fortunately mostly useful stuff in between the two.
There are serious issues with trust and security that inhibit the average Node.js development’s push to production spotlight. But for now, we as a community, like to close our eyes and hope for the best.
Only time will tell if this tactic will pay off, but NPM is here to stay (for now).
There were a lot of interesting security issues and topics I researched during this whole process. While I would have liked to include those in this post, it had already become a wall of text. So I will most probably write another wall of text to cover those sometime in the future.
In the mean time those of you with an interest in security feel free to check out my book “Secure Your Node.js Web Application”


